این راهنمای پرامپت نویسی ChatGPT دقیقاً به شما نشان میدهد چه درخواستهایی مطرح کنید و از چه تکنیکهایی استفاده کنید تا هر بار پاسخهایی دقیقتر، کاربردیتر و مرتبطتر دریافت کنید.
حتماً این حس را تجربه کردهاید: روبهروی ChatGPT نشستهاید، انگشتانتان روی کیبورد معلق مانده، اما دقیقاً نمیدانید چطور درخواستتان را بنویسید تا بهترین پاسخ ممکن را بگیرید. اگر اینطور است، تنها نیستید. بسیاری از کاربران ChatGPT هر چیزی که به ذهنشان میرسد تایپ میکنند و امیدوارند نتیجه خوبی بگیرند.
اهمیت پرامپت نویسی مؤثر برای هوش مصنوعی
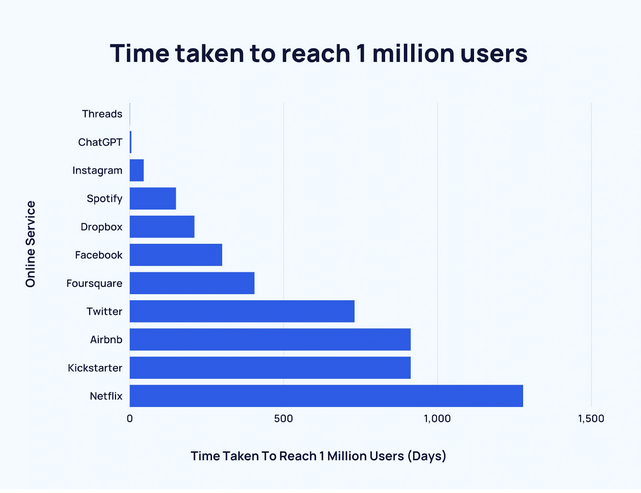
هوش مصنوعی قادر است کارهای شگفتانگیزی انجام دهد. همین موضوع باعث شده ChatGPT در میان ۱۰ وبسایت پربازدید جهان قرار بگیرد. نکته جالبتر اینکه این ابزار تنها ۵ روز پس از عرضه در نوامبر ۲۰۲۲ به یک میلیون کاربر رسید.
اما با وجود این قدرت، کیفیت خروجی ChatGPT تا حد زیادی به نحوه طرح سؤال شما بستگی دارد.
سؤال درست، پاسخ دقیقتر
برای مثال، اگر بهدنبال پاسخی متعادل و واقعبینانه هستید، بهجای یک سؤال کلی، میتوانید بپرسید:
«دورکاری چه تأثیرات مثبت و منفیای بر بهرهوری دارد؟»
چنین سؤالی به هوش مصنوعی کمک میکند هر دو جنبه موضوع را در نظر بگیرد و پاسخی جامعتر ارائه دهد.



مشکل رایج: ندادن زمینه (Context) مناسب
هوش مصنوعی «بین خطوط را نمیخواند». اگر پاسخی که دریافت میکنید بیش از حد کلی است یا جزئیات مهمی را نادیده میگیرد، معمولاً مشکل از پرامپت اولیه است، نه از خود AI.
زمینه یا Context به هوش مصنوعی میگوید چه چیزهایی اهمیت بیشتری دارند؛ از جمله:
- مخاطب کیست؟
- هدف محتوا چیست؟
- خروجی نهایی چه شکلی باید داشته باشد؟

هوش مصنوعی میتواند هر چیزی را از خلاصهای یک جملهای گرفته تا یک صفحه کامل از جزئیات به شما ارائه دهد.

آیا خلاصهای در سه نکته برای مدیران میخواهید؟

پاراگرافی که برای مبتدیان نوشته شده باشد؟
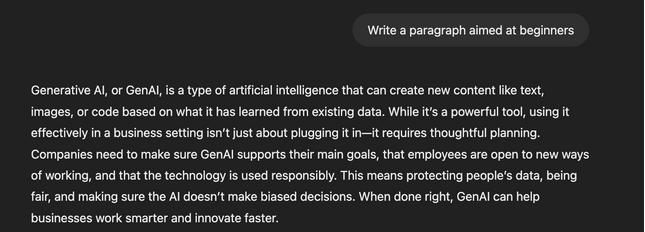
هرچه زمینه مرتبطتری داشته باشد، احتمال اینکه پاسخی متناسب با نیازهای شما ارائه دهد، بیشتر است.
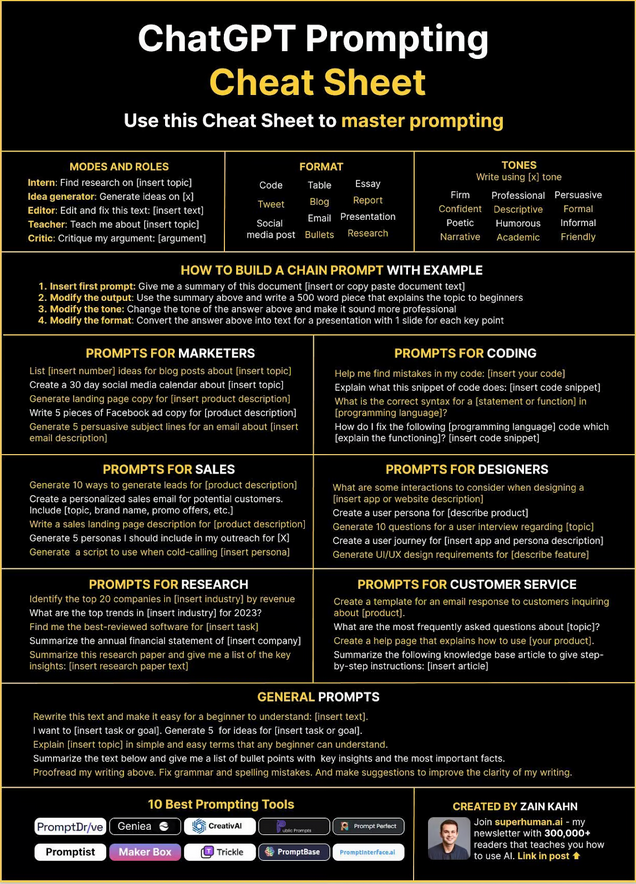
یک مثال ساده
فرض کنید از ChatGPT بخواهید: «این مقاله را خلاصه کن.»
بدون اطلاعات بیشتر، خروجی میتواند هر چیزی باشد:
- یک جمله کوتاه
- یا یک خلاصه چند پاراگرافی
اما اگر از ابتدا مشخص کنید:
- «خلاصه در سه بولت برای مدیران اجرایی»
- یا «یک پاراگراف ساده برای افراد مبتدی»
احتمال اینکه پاسخ دقیقاً مطابق نیاز شما باشد، بسیار بیشتر میشود. هرچه زمینه مرتبطتری بدهید، خروجی هوشمندانهتری میگیرید.
نمونههایی از پرامپت مؤثر
یک سؤال خوب میتواند تفاوت بزرگی ایجاد کند. فرقی نمیکند:
- بازاریاب باشید
- برنامهنویس یا توسعهدهنده
- طراح UI/UX
- یا عضو تیم پشتیبانی مشتریان
در هر صنعتی که فعالیت میکنید، نوشتن پرامپتهای مؤثر به شما کمک میکند بیشترین بهره را از ChatGPT ببرید.
در ادامه خواهید دید که چگونه میتوان برای وظایف مختلف، درخواستها را به شکلی دقیقتر و هدفمندتر مطرح کرد تا پاسخهایی مرتبطتر و کاربردیتر دریافت شود.
پرامپت پیشنهادی برای بازاریابها (Prompts for Marketers)
ChatGPT میتواند به شکل چشمگیری در صرفهجویی زمان بازاریابها مؤثر باشد. از تولید ایدههای محتوایی گرفته تا نوشتن پستهای جذاب شبکههای اجتماعی و حتی برنامهریزی کمپینهای بازاریابی، این ابزار میتواند نقش یک دستیار همهفنحریف را ایفا کند.
اگر قصد دارید متنهای تبلیغاتی تأثیرگذار بنویسید یا برای یک کمپین جدید ایدهپردازی کنید، بهتر است بهجای درخواستهای کلی، هدف، لحن و مخاطب خود را بهروشنی مشخص کنید.
در ادامه، چند نمونه پرامپت کاربردی برای موقعیتهای مختلف بازاریابی آورده شده است:
- متن لندینگ پیج
«برای محصولی که به [گروه هدف] کمک میکند تا [وظیفه مشخص] را مدیریت کنند، متن یک لندینگ پیج بنویس. لحن متن [حرفهای / دوستانه / محاورهای / رسمی / غیررسمی / جذاب] باشد و ویژگیهای کلیدی و مزایای مهم محصول [ذکر ویژگیها] را برجسته کن.» - کپی تبلیغاتی برای کمپین فیسبوک
«برای یک کمپین تبلیغاتی فیسبوک، متن تبلیغاتی محصول [نام محصول] را بنویس که مخاطب هدف آن [گروه هدف] هستند. توضیح بده چگونه [مزیت اصلی] میتواند با [روتین یا سبک زندگی مخاطب] آنها هماهنگ شود. لحن متن [حرفهای / دوستانه / محاورهای / رسمی / غیررسمی / جذاب] و رویکرد آن [توصیف رویکرد] باشد.» - پست شبکه اجتماعی برای معرفی محصول جدید
«یک پست برای [نام پلتفرم شبکه اجتماعی] بنویس که لانچ محصول [نام محصول] را اعلام میکند. تمرکز روی [ویژگی کلیدی] و مزیت [فایده مشخص] باشد. متن را [کوتاه / خلاصه / جذاب] نگه دار.» - استراتژی محتوایی برای وبلاگ
«یک استراتژی محتوایی برای وبلاگی با موضوع [موضوع یا صنعت] طراحی کن. این استراتژی باید شامل ایده موضوعی پستها، مخاطب هدف و زمانبندی انتشار باشد و با [اهداف مشخص] همراستا بوده و مراحل اجرایی قابلاقدام ارائه دهد.» - کمپین ایمیل مارکتینگ
«یک توالی ۵ ایمیلی برای پرورش لیدها (Lead Nurturing) برای محصول [نام محصول] با مخاطب [گروه هدف] بنویس. لحن ایمیلها [حرفهای / دوستانه / محاورهای / رسمی / غیررسمی / جذاب] باشد و روی چالش [نقطه درد مخاطب] تمرکز کند و نشان دهد محصول چگونه فرایند [راهحل] را سادهتر میکند.» - برنامه معرفی (Referral Program)
«متن یک لندینگ پیج برای برنامه معرفی محصول [نام محصول] بنویس. مزایای این برنامه را هم برای معرفیکننده و هم برای دریافتکننده توضیح بده و لحن متن [دوستانه / محاورهای] باشد.»
پرامپت پیشنهادی برای برنامهنویسی (Prompts for Coding)
اگر از هوش مصنوعی برای کدنویسی استفاده میکنید، دقت در دستورالعملها حیاتی است. هرچه زمینه بیشتری درباره مشکل خود ارائه دهید، احتمال دریافت پاسخ دقیقتر بیشتر میشود.
بهجای درخواست کدهای کلی، روی قابلیت موردنظر، زبان برنامهنویسی یا الگوریتم مشخص تمرکز کنید.
نمونههایی از پرامپتهای مؤثر:
- کمک در دیباگ
«در کد [زبان برنامهنویسی] با خطای [پیام خطا] مواجه شدهام. قصد دارم [شرح کار] را انجام دهم اما نمیدانم چرا اجرا نمیشود. این هم کد: [کد]. لطفاً مشکل را بررسی کن.» - نوشتن تابع
«یک تابع در زبان [زبان برنامهنویسی] بنویس که [شرح وظیفه] را انجام دهد. تابع باید این شرایط را رعایت کند: [شرایط یا محدودیتها].» - بهینهسازی کد موجود
«این کد [زبان برنامهنویسی] که وظیفه [شرح وظیفه] را دارد بهینه کن. پیادهسازی فعلی برای [دلیل] بیش از حد [کند / ناکارآمد] است.» - مدیریت درخواست API
«یک تابع در زبان [زبان برنامهنویسی] بنویس که یک درخواست API ارسال کند، داده [نوع داده] را برای [هدف مشخص] دریافت کند، پاسخ را مدیریت کرده و دادهها را پردازش کند.» - نوشتن تست واحد (Unit Test)
«برای تابعی در زبان [زبان برنامهنویسی] که [وظیفه] را انجام میدهد تست واحد بنویس. تستها باید حالتهای معتبر و نامعتبر را پوشش دهند تا Edge Caseها بررسی شوند.»
پرامپت پیشنهادی برای فروش (Prompts for Sales)
تیمهای فروش میتوانند از AI برای نوشتن ایمیلهای فروش، آمادهسازی ارائهها و تحلیل دادههای مشتری استفاده کنند. نکته کلیدی این است که درخواستها باید با مرحله مشتری در قیف فروش هماهنگ باشند.
نمونه پرامپتها:
- ایمیل فروش برای لید جدید
«یک ایمیل فروش شخصیسازیشده برای مشتری بالقوهای بنویس که در حوزه [کسبوکار مشخص] فعالیت میکند. توضیح بده محصول ما چگونه مشکل [چالش مشخص] را حل میکند و چه مزایای دیگری دارد. لحن ایمیل [حرفهای / دوستانه] باشد.» - پیچ فروش برای محصول SaaS
«یک متن معرفی فروش برای محصول SaaS بنویس که به شرکتها در [عملکرد تجاری مشخص] کمک میکند. مخاطب هدف [سمت شغلی] در [نوع کسبوکار] است. مزایای کلیدی مانند [ویژگی ۱]، [ویژگی ۲] و [ویژگی ۳] را برجسته کن.» - سؤالات ارزیابی لید
«۵ سؤال برای ارزیابی یک لید بالقوه برای محصول [نام محصول] طراحی کن. سؤالات روی [ابزارهای فعلی / چالشها / نیازها] و راهحل موردنظر تمرکز داشته باشند.» - ایمیل پیگیری پس از جلسه
«یک ایمیل پیگیری بعد از جلسه فروش برای محصول [نام محصول] بنویس. نکات اصلی مطرحشده را مرور کن، به سؤالات باقیمانده پاسخ بده و [گام بعدی] را پیشنهاد کن.» - پاسخ به اعتراض مشتری
«پاسخی برای مشتریای بنویس که درباره [اعتراض مشخص] نگرانی دارد. این نگرانی را با تأکید بر [مزایای مشخص] برطرف کن و یک [راهحل یا جایگزین] ارائه بده.»
پرامپت پیشنهادی برای طراحان (Prompts for Designers)
طراحان میتوانند از هوش مصنوعی برای ایدهپردازی، انتخاب پالت رنگ، یا حتی طراحی نسخه اولیه پروژهها استفاده کنند. اما پرامپتهای کلی مثل «برای من طراحی کن» معمولاً نتیجه خوبی نمیدهند.
جزئیات طراحی، حسوحال (Mood) و مخاطب هدف را مشخص کنید.
نمونهها:
- ایده طراحی لوگو
«یک لوگو با سبک [سبک طراحی] برای یک [نوع کسبوکار] طراحی کن که حسوحال [ویژگی احساسی] را منتقل کند. رنگهای اصلی [رنگ اصلی] و [رنگ دوم] باشند. طراحی باید هم [ویژگی] و هم [ویژگی] باشد.» - چیدمان صفحه وب
«چیدمان صفحه اصلی یک وبسایت با سبک [سبک طراحی] برای [نوع کسبوکار] طراحی کن. بخشهایی مثل [عناصر مشخص] را در نظر بگیر. طراحی کلی باید [صفت] و کاربرپسند باشد.» - گرافیک پست شبکه اجتماعی
«یک گرافیک برای پست [پلتفرم اجتماعی] طراحی کن که محصول یا رویداد [نام] را معرفی کند. از پالت رنگی [رنگها] استفاده کن و پیام [پیام کلیدی] را در طراحی بگنجان.» - بازخورد UI/UX
«این طراحی UI برای اپلیکیشن [نوع اپ] را بررسی کن و درباره [مسئله خاص] مثل سهولت ناوبری، وضوح [ویژگی] و جریان کلی کاربر بازخورد بده.»
پرامپت پیشنهادی برای تحقیق و پژوهش (Prompts for Research)
ChatGPT میتواند در تحلیل دادهها، شناسایی روندها و خلاصهسازی پژوهشها بسیار مفید باشد. برای دریافت خروجی باکیفیت، دامنه و هدف تحقیق را شفاف مشخص کنید.
نمونه پرامپتها:
- خلاصه مرور ادبیات
«یافتههای کلیدی پژوهشهای انجامشده در [بازه زمانی] درباره [موضوع مشخص] را خلاصه کن و روی [جنبهها یا زیرموضوعها] تمرکز داشته باش.» - تحلیل داده
«دادههای [بازه زمانی] را تحلیل کن، روندها و الگوها را شناسایی کن و مشخص کن کدام [دسته یا بخش] بهترین عملکرد را داشته است. دلایل احتمالی [افت یا رشد] را پیشنهاد بده.» - خلاصه تحقیقات بازار
«خلاصهای از تحقیقات اخیر بازار درباره رفتار مصرفکنندگان در صنعت [نام صنعت] ارائه بده و روی [ترجیحات، الگوهای خرید، حساسیت قیمتی] تمرکز کن.» - تحلیل رقبا
«یک تحلیل رقابتی برای ورود محصول جدید [نوع محصول] به بازار انجام بده. رقبا، استراتژیهای قیمتگذاری و مزیتهای رقابتی را بررسی کن.» - گزارش روندهای صنعت
«گزارش روندهای صنعت [نام صنعت] در [بازه زمانی] را تهیه کن. فناوریهای نوظهور، تغییرات بازار، رفتار مصرفکننده و تحولات قانونی را پوشش بده.» - طراحی پرسشنامه نظرسنجی
«[تعداد] سؤال نظرسنجی برای مخاطب [گروه هدف] طراحی کن تا میزان رضایت آنها از [محصول یا خدمت] سنجیده شود. سؤالات شامل بخشهای کیفی و کمی باشند.»
پرامپت پیشنهادی برای پشتیبانی مشتری (Prompts for Customer Service)
ChatGPT میتواند در پاسخگویی به سؤالات تکراری، مدیریت شکایات و حتی عیبیابی مشکلات رایج مشتریان کمک کند. اما برای دریافت پاسخ مناسب، باید مشکل مشتری و لحن پاسخ را دقیق مشخص کنید.
نمونهها:
- پاسخ به شکایت مشتری
«یک ایمیل پشتیبانی برای مشتریای بنویس که از [محصول مشخص] ناراضی است. بابت مشکل پیشآمده عذرخواهی کن، [بازگشت وجه / تعویض] پیشنهاد بده و درباره کیفیت محصولات اطمینان بده.» - راهنمای عیبیابی
«یک راهنمای مرحلهبهمرحله برای حل مشکل رایج مشتریان در استفاده از [محصول مشخص] بنویس و راهحلها را ساده و قابلفهم توضیح بده.» - درخواست بازخورد مشتری
«یک ایمیل محترمانه برای درخواست بازخورد از مشتریای که اخیراً از [خدمت مشخص] استفاده کرده بنویس و او را به ارائه پیشنهاد تشویق کن.» - تأخیر در ارسال سفارش
«ایمیلی بنویس که تأخیر در ارسال سفارش را به مشتری اطلاع میدهد، بابت آن عذرخواهی میکند، زمان تحویل جدید را اعلام میکند و یک [تخفیف / ارسال رایگان] پیشنهاد میدهد.» - ایمیل Upsell
«ایمیلی برای مشتریای بنویس که نسخه پایه [محصول] را خریداری کرده و او را به ارتقا به نسخه [پریمیوم] دعوت کن. ویژگیها و مزایای اضافه نسخه جدید را توضیح بده.»
همگام با جدیدترین ترندهای هوش مصنوعی بمانید
این راهنمای پرامپتنویسی ChatGPT به پایان رسید. امیدواریم اکنون آمادگی بیشتری برای استفاده حرفهای از هوش مصنوعی در کارهای روزمره خود داشته باشید.
چه در حال بهینهسازی جریان کاری باشید، چه درگیر یک چالش فنی یا بازطراحی استراتژی بازاریابی، ابزارها و نکات مطرحشده میتوانند به شما کمک کنند به تسلط واقعی بر ChatGPT برسید.
برای اطلاع از اخبار مرتبط با هوشمصنوعی و راهنماهای پرامپتنویسی، میتوانید بخش «هوش مصنوعی» کدرزنیوز را دنبال کنید.